ROAPI Documentation
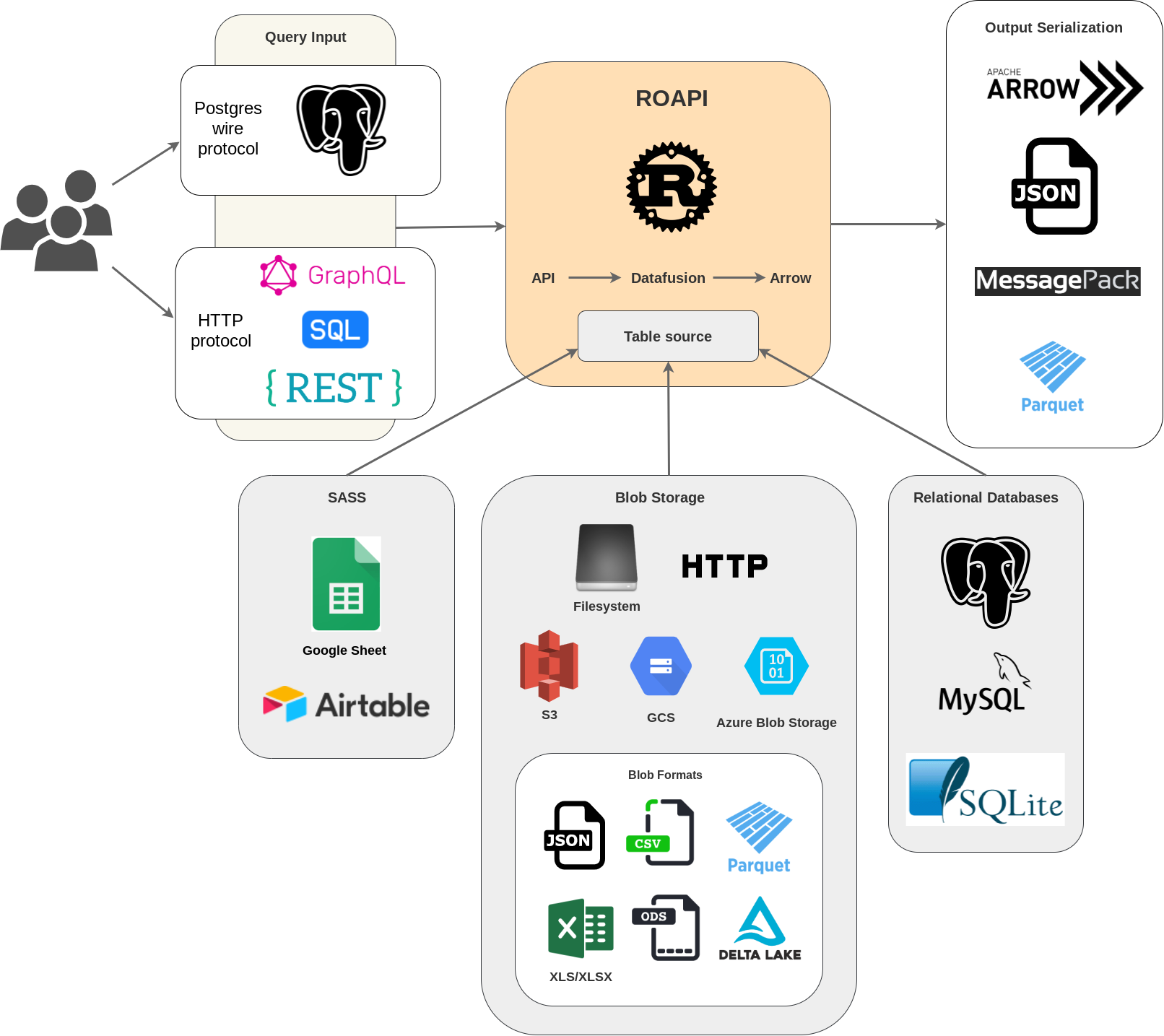
ROAPI automatically spins up read-only APIs and query frontends for slowly moving datasets without requiring you to write a single line of code. It builds on top of Apache Arrow and Datafusion. The core of its design can be boiled down to the following:
- Query frontends to translate SQL, GraphQL and REST API queries into Datafusion plans.
- Datafusion for query plan execution.
- Data layer to load datasets from a variety of sources and formats with automatic schema inference.
- Response encoding layer to serialize intermediate Arrow record batch into various formats requested by client.
Its pluggable query core design makes it possible for users to efficiently perform join queries across a diverse set of datasources from simple CSV/Parquet files in Data warehouses, to MySQL/Postgres, to SASS like Google spreadsheet.
See below for a high level design diagram:
If you'd like to share feedback on how you're using ROAPI, please fill out this survey. Thanks!
Installation
Pre-built binary
Platform specific pre-built binaries for each release are hosted on our Github release page.
You can download and install them with a single command using pip:
pip install roapi
If you are using homebrew, you can also install using brew command:
brew install roapi
# notice that the binary itself is still roapi-http
Docker
Pre-built docker images are hosted at ghcr.io/roapi/roapi.
Build from source
You need to install Rust toolchain if you haven't done so.
cargo install --locked --git https://github.com/roapi/roapi --branch main --bins roapi
Quick start
Spin up APIs for test_data/uk_cities_with_headers.csv and
test_data/spacex-launches.json:
roapi \
--table "uk_cities=test_data/uk_cities_with_headers.csv" \
--table "test_data/spacex_launches.json"
Or using prebuilt docker image:
docker run -t --rm -p 8080:8080 ghcr.io/roapi/roapi:latest --addr-http 0.0.0.0:8080 \
--table "uk_cities=test_data/uk_cities_with_headers.csv" \
--table "test_data/spacex_launches.json"
Query API
Query tables using SQL, GraphQL or REST:
curl -X POST -d "SELECT city, lat, lng FROM uk_cities LIMIT 2" localhost:8080/api/sql
curl -X POST -d "query { uk_cities(limit: 2) {city, lat, lng} }" localhost:8080/api/graphql
curl "localhost:8080/api/tables/uk_cities?columns=city,lat,lng&limit=2"
Sample response:
[
{
"city": "Elgin, Scotland, the UK",
"lat": 57.653484,
"lng": -3.335724
},
{
"city": "Stoke-on-Trent, Staffordshire, the UK",
"lat": 53.002666,
"lng": -2.179404
}
]
See Query frontends for details on different operators supported by each frontend.
Schema API
Get inferred schema for all tables:
curl localhost:8080/api/schema
Sample response:
{
"uk_cities": {
"fields": [
{
"name": "city",
"data_type": "Utf8",
"nullable": false,
"dict_id": 0,
"dict_is_ordered": false
},
{
"name": "lat",
"data_type": "Float64",
"nullable": false,
"dict_id": 0,
"dict_is_ordered": false
},
{
"name": "lng",
"data_type": "Float64",
"nullable": false,
"dict_id": 0,
"dict_is_ordered": false
}
]
}
}
Config
Command line argument
You can configure ROAPI to load as many tables as you want by repeating the --table argument:
roapi --table 'table1_name=table1_uri' --table 'table2_name=table2_uri'
You can use RUST_LOG environment variable to control the logging verbosity:
RUST_LOG=debug roapi ...
Here is the output from roapi --help:
roapi 0.7.1
QP Hou
Create full-fledged APIs for static datasets without writing a single line of code.
USAGE:
roapi [OPTIONS]
OPTIONS:
-a, --addr-http <IP:PORT>
HTTP endpoint bind address
-c, --config <config>
config file path
-d, --disable-read-only
Start roapi in read write mode
-h, --help
Print help information
-p, --addr-postgres <IP:PORT>
Postgres endpoint bind address
-t, --table <[table_name=]uri[,option_key=option_value]>
Table sources to load. Table option can be provided as optional setting as part of the
table URI, for example: `blogs=s3://bucket/key,format=delta`. Set table uri to `stdin`
if you want to consume table data from stdin as part of a UNIX pipe. If no table_name is
provided, a table name will be derived from the filename in URI.
-V, --version
Print version information
YAML config
Tables
You can configure multiple table sources using YAML config, which supports more advanced format specific table options. For example:
addr:
# binding address for TCP port that speaks HTTP protocol
http: 0.0.0.0:8080
# binding address for TCP port that speaks Postgres wire protocol
postgres: 0.0.0.0:5432
tables:
- name: "blogs"
uri: "test_data/blogs.parquet"
- name: "ubuntu_ami"
uri: "test_data/ubuntu-ami.json"
option:
format: "json"
pointer: "/aaData"
array_encoded: true
schema:
columns:
- name: "zone"
data_type: "Utf8"
- name: "name"
data_type: "Utf8"
- name: "version"
data_type: "Utf8"
- name: "arch"
data_type: "Utf8"
- name: "instance_type"
data_type: "Utf8"
- name: "release"
data_type: "Utf8"
- name: "ami_id"
data_type: "Utf8"
- name: "aki_id"
data_type: "Utf8"
- name: "spacex_launches"
uri: "https://api.spacexdata.com/v4/launches"
option:
format: "json"
- name: "github_jobs"
uri: "https://web.archive.org/web/20210507025928if_/https://jobs.github.com/positions.json"
Key value stores
Table sources can be loaded into in-memory key value stores if you specify which two columns to be used to load keys and values in the config:
kvstores:
- name: "spacex_launch_name"
uri: "test_data/spacex_launches.json"
key: id
value: name
The above config will create a keyvalue store named spacex_launch_name that allows you to lookup SpaceX launch names using launch ids.
DataFusion configuration
You can override DataFusion configuration settings by specifying them in the datafusion section of your config file. This allows you to tune the query engine's behavior for your specific use case:
datafusion:
"execution.collect_statistics": "true"
"execution.batch_size": "8192"
"sql_parser.enable_ident_normalization": "true"
The datafusion field accepts a map of configuration key-value pairs where
both keys and values are strings. You can reference the DataFusion configuration documentation
for a complete list of available configuration options.
Specify a config file on startup
Use -c argument to run ROAPI using a specific config file:
roapi -c ./roapi.yml
Dataset formats
JSON
When a table uri ends in .json, ROAPI will try to load it as JSON table if no
format option is specified:
tables:
- name: "mytable"
uri: "http://mytable.json"
Filter by JSON pointer
Sometimes the JSON array you want to serve might be stored inside a JSON object. To support this use-case, ROAPI supports loading JSON using a JSON pointer.
Take the following JSON data as an example:
{
"x": {
"y": [{"col1": "z"}, {"col1": "zz"}]
}
}
In order to only serve [{"col1": "z"}, {"col1": "zz"}] through ROAPI, you can
configure the JSON table source as:
tables:
- name: "mytable"
uri: "http://mytable.json"
option:
format: "json"
pointer: "/x/y"
Array encoding
Each row in JSON data can be encoded using array for size reduction. This convention allows us to avoid repeating column names in every row.
For example:
[
{"col1": 1, "col2": "abc"},
{"col1": 2, "col2": "efg"}
]
Can be stored as:
[
[1, "abc"],
[2, "efg"]
]
However, when loading JSON rows using array encoding, you must explicitly specify the schema, since there is no column name in the datasource anymore for ROAPI to perform the schema inference.
tables:
- name: "mytable"
uri: "http://mytable.json"
option:
format: "json"
array_encoded: true
schema:
columns:
- name: "col1"
data_type: "Int64"
- name: "col2"
data_type: "Utf8"
Parquet
When a table uri ends in .parquet, ROAPI will try to load it as Parquet table if no
format option is specified:
tables:
- name: "mytable"
uri: "http://mytable.parquet"
You can partition a Parquet dataset into multiple partitions and load all of them into a single table by directory path:
tables:
- name: "mytable"
uri: "./table_dir"
option:
format: "parquet"
Large Datasets
ROAPI loads the entire table into memory as the default behavior. If your
table is large or you want to avoid loading all data during startup, you can
set an additional option use_memory_table: false (default: true). With that
configuration, ROAPI will not copy the data into memory, but instructs datafusion
to directly operate on the backing storage.
At the moment, this comes with the following limitations:
- no nested schema: datafusion#83
- missing support for cloud storage: datafusion#616
Example:
tables:
- name: "mytable"
uri: "./table_dir"
option:
format: "parquet"
use_memory_table: false
Note that when providing use_memory_table option, it becomes necessary to
also specify the format.
CSV
When a table uri ends in .csv, ROAPI will try to load it as CSV table if no
format option is specified:
tables:
- name: "mytable"
uri: "http://mytable.csv"
You can partition a CSV dataset into multiple partitions and load all of them into a single table by directory path:
tables:
- name: "mytable"
uri: "./table_dir"
option:
format: "csv"
Google spreadsheet
To serve a Google spreadsheet as API, you need to gather the following config values:
- Google spreadsheet URL, usually in the form of
https://docs.google.com/spreadsheets/d/{SPREADSHEET_ID}#gid={SHEET_ID}. - (Optional) Google spreadsheet sheet title (bottom of the spreadsheet UI).
This is required if
SHEET_IDis not specified in URL through#gid. - Google spreadsheet service account secret key.
Here are the steps to configure the service account:
- Activate Google Sheets API in the Google API Console.
- Create a service account: https://console.developers.google.com/apis/api/sheets.googleapis.com/credentials.
- Go into service account setting, click
ADD KEY->Create new key. Then select JSON format and save it somewhere safe as a file.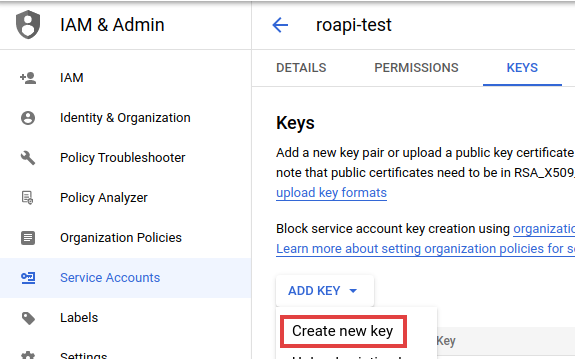
- Copy email address for your newly created service account, usually in the format of
{ACCOUNT_NAME}@{PROJECT_ID}.iam.gserviceaccount.com.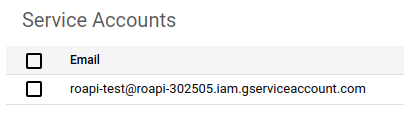
- Open the Google spreadsheet that you want to serve, then share it with the newly created service
account using the service account email.
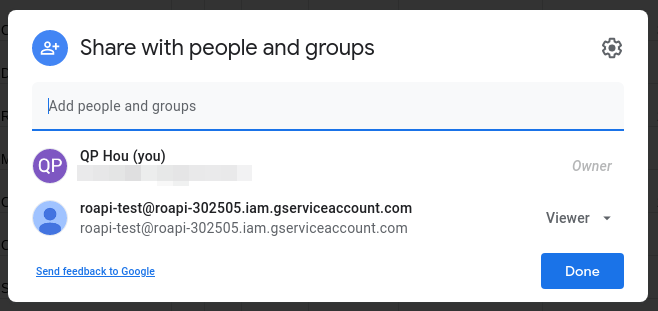
Now you can configure ROAPI to load the google spreadsheet into a table using:
tables:
- name: "table_name"
uri: "https://docs.google.com/spreadsheets/d/1-lc4oij04aXzFSRMwVBLjU76s-K0-s6UPc2biOvtuuU#gid=0"
option:
format: "google_spreadsheet"
application_secret_path: "path/to/service_account_key.json"
# sheet_title is optional if `#gid` is specified in uri
sheet_title: "sheet_name_within_google_spreadsheet"
ROAPI only invokes Google Sheets API during the initial data load, subsequent query requests are served using in memory data.
Example
Here is what it looks like to serve this public google spreadsheet with ROAPI.
Start server:
$ roapi -c local.yaml
[2022-05-31T01:07:55Z INFO roapi::context] loading `uri(https://docs.google.com/spreadsheets/d/1-lc4oij04aXzFSRMwVBLjU76s-K0-s6UPc2biOvtuuU#gid=0)` as table `properties`
[2022-05-31T01:07:56Z INFO roapi::context] registered `uri(https://docs.google.com/spreadsheets/d/1-lc4oij04aXzFSRMwVBLjU76s-K0-s6UPc2biOvtuuU#gid=0)` as table `properties`
[2022-05-31T01:07:56Z INFO roapi::startup] 🚀 Listening on 127.0.0.1:5432 for Postgres traffic...
[2022-05-31T01:07:56Z INFO roapi::startup] 🚀 Listening on 127.0.0.1:8080 for HTTP traffic...
Query through Postgres wire protocol:
$ psql -h 127.0.0.1
psql (12.10 (Ubuntu 12.10-0ubuntu0.20.04.1), server 13)
WARNING: psql major version 12, server major version 13.
Some psql features might not work.
Type "help" for help.
houqp=> select "Address", "Bed", "Bath", "Occupied" from properties;
Address | Bed | Bath | Occupied
------------------+-----+------+----------
Bothell, WA | 3 | 2 | f
Lynnwood, WA | 2 | 1 | f
Kirkland, WA | 4 | 2 | f
Kent, WA | 3 | 2 | f
Mount Vernon, WA | 2 | 1 | f
Seattle, WA | 3 | 1 | f
Seattle, WA | 2 | 1 | f
Shoreline, WA | 1 | 1 | f
Bellevue, WA | 3 | 1 | f
Renton, WA | 4 | 2 | f
Woodinville, WA | 3 | 3 | f
Kenmore, WA | 4 | 3 | f
Fremont, WA | 5 | 3 | f
Redmond, WA | 2 | 2 | f
Mill Creek, WA | 3 | 3 | f
(15 rows)
Query with aggregation using HTTP SQL frontend:
$ curl -s -X POST localhost:8080/api/sql --data-binary @- <<EOF | jq
SELECT DISTINCT("Landlord"), COUNT("Address")
FROM properties
GROUP BY "Landlord"
EOF
[
{
"Landlord": "Carl",
"COUNT(properties.Address)": 3
},
{
"Landlord": "Roger",
"COUNT(properties.Address)": 3
},
{
"Landlord": "Mike",
"COUNT(properties.Address)": 4
},
{
"Landlord": "Sam",
"COUNT(properties.Address)": 2
},
{
"Landlord": "Daniel",
"COUNT(properties.Address)": 3
}
]
Query with filter using HTTP GraphQL frontend:
$ curl -s -X POST localhost:8080/api/graphql --data-binary @- <<EOF | jq
query {
properties(
filter: {
Bed: { gt: 3 }
Bath: { gte: 3 }
}
sort: [
{ field: "Bed", order: "desc" }
]
) {
Address
Bed
Bath
Monthly_Rent
}
}
EOF
[
{
"Address": "Fremont, WA",
"Bed": 5,
"Bath": 3,
"Monthly_Rent": "$4,500"
},
{
"Address": "Kenmore, WA",
"Bed": 4,
"Bath": 3,
"Monthly_Rent": "$4,000"
}
]
Note: when inferring table schema from Google spreadsheets, ROAPI automatically
replaces spaces in column names with _(underscore).
NDJSON
NDJSON stands for Newline delimited JSON. It is a convenient format for storing or streaming structured data that may be processed one record at a time.
When a table uri ends in .ndjson, ROAPI will try to load it as NDJSON table
if no format option is specified:
tables:
- name: "mytable"
uri: "http://mytable.ndjson"
Delta Lake
ROAPI supports loading Delta tables from Delta Lake
through delta-rs. Since a Delta table
doesn't have an extension suffix, ROAPI cannot infer table format from table
URI alone. Therefore, the format option needs to be set to delta
explicitly for Delta table sources:
tables:
- name: "mytable"
uri: "s3://bucket/delta_table/path"
option:
format: "delta"
Large Datasets
ROAPI loads the entire table into memory as the default behavior. If your
table is large or you want to avoid loading all data during startup, you can
set an additional option use_memory_table: false (default: true). With that
configuration, ROAPI will not copy the data into memory, but instructs datafusion
to directly operate on the backing storage.
At the moment, this comes with the following limitations:
- no nested schema: datafusion#83
- missing support for cloud storage: datafusion#616
Example:
tables:
- name: "mytable"
uri: "./path/to/delta_table"
option:
format: "delta"
use_memory_table: false
Note that when providing use_memory_table option, it becomes necessary to
also specify the format.
Arrow
When a table uri ends in .arrow or .arrows, ROAPI will try to load it as
Arrow IPC file or stream if no format option is specified:
tables:
- name: "mytable"
uri: "http://mytable.arrow" # or .arrows
You can partition an Arrow dataset into multiple partitions and load all of them into a single table by directory path:
tables:
- name: "mytable"
uri: "./table_dir"
option:
format: "arrow" # or arrows
Excel
ROAPI supports loading Microsoft Excel compatible formats including xls, xlsx, xlsb, and ods files.
tables:
- name: "mytable"
uri: "path/to/file.xlsx"
option:
format: "xlsx"
sheet_name: "Sheet1"
Supported Formats
- xls - Microsoft Excel 5.0/95 Workbook
- xlsx - Excel Workbook
- xlsb - Excel Binary Workbook
- ods - OpenDocument Spreadsheet
Sheet Selection
You can specify which sheet to load from the spreadsheet using the sheet_name option. By default, ROAPI will use the first sheet if no sheet name is specified.

tables:
- name: "mytable"
uri: "path/to/file.xlsx"
option:
format: "xlsx"
sheet_name: "MyDataSheet"
Table Range Options
You can specify a specific range of cells to load from the spreadsheet: You can specify a specific range of cells to load from the spreadsheet:
- rows_range_start - The first row of the table containing column names (default: 0)
- rows_range_end - The last row of the table (default: all rows)
- columns_range_start - The first column of the table (default: 0)
- columns_range_end - The last column of the table (default: all columns)
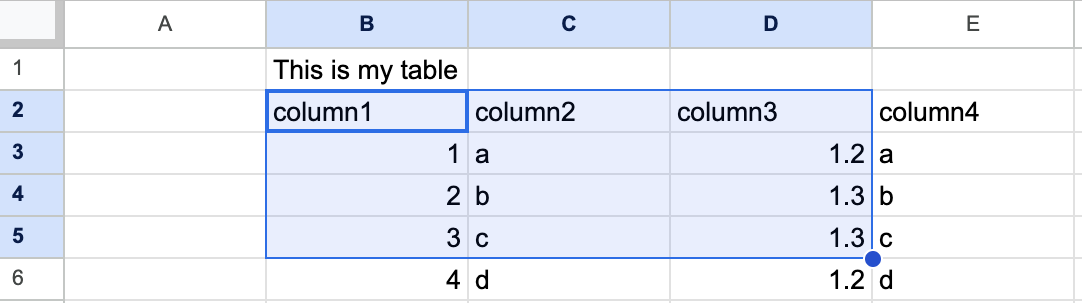
tables:
- name: "mytable"
uri: "path/to/file.xlsx"
option:
format: "xlsx"
sheet_name: "Sheet1"
rows_range_start: 1
rows_range_end: 4
columns_range_start: 1
columns_range_end: 3
Schema Inference
ROAPI can automatically infer the schema from your Excel data. The first row within the specified range is treated as column names, and ROAPI will analyze the remaining rows to determine data types.
You can control schema inference with the schema_inference_lines option, which specifies how many rows to analyze (including the header row). For example, schema_inference_lines: 3 will use the first row for column names and analyze 2 additional rows for data types.
If a column contains mixed data types (like both integers and floats), ROAPI will default to the Utf8 (string) data type.
Explicit Schema Definition
For better performance and predictable data types, you can define the schema explicitly in your configuration:
tables:
- name: "excel_table"
uri: "path/to/file.xlsx"
option:
format: "xlsx"
schema:
columns:
- name: "int_column"
data_type: "Int64"
nullable: true
- name: "string_column"
data_type: "Utf8"
nullable: true
- name: "float_column"
data_type: "Float64"
nullable: true
- name: "datetime_column"
data_type: !Timestamp [Seconds, null]
nullable: true
- name: "duration_column"
data_type: !Duration Second
nullable: true
- name: "date32_column"
data_type: Date32
nullable: true
- name: "date64_column"
data_type: Date64
nullable: true
- name: "null_column"
data_type: Null
nullable: true
Blob store
ROAPI currently supports the following blob storages:
- Filesystem
- HTTP/HTTPS
- S3
- GCS
- Azure Storage
Filesystem
Filesystem store can be specified using file: or filesystem: schemes. In a
Windows environment, the scheme is mandatory. On Unix systems, a uri without a
scheme prefix is treated as filesystem backed data source by ROAPI.
For example, to serve a local parquet file test_data/blogs.parquet, you can
just set the uri to the file path:
tables:
- name: "blogs"
uri: "test_data/blogs.parquet"
Filesystem store supports loading partitioned tables. In other words, you can split up the table into mulitple files and load all of them into a single table by setting uri to the directory path. When loading a partitioned dataset, you will need to manually specify table format since the uri will not contain table format as a suffix:
tables:
- name: "blogs"
uri: "test_data/blogs/"
option:
format: "parquet"
HTTP/HTTPS
ROAPI can build tables from datasets served through HTTP protocols. However, one thing to keep in mind is HTTP store doesn't support partitioned datasets because there is no native directory listing support in the HTTP protocol.
To set custom headers for HTTP requests, you can use the headers io option:
tables:
- name: "TABLE_NAME"
uri: "http://BUCKET/TABLE/KEY.csv"
io_option:
headers:
'Content-Type': 'application/json'
Authorization: 'Bearer TOKEN'
S3
ROAPI can build tables from datasets hosted in S3 buckets. Configuration is similar to filesystem store:
tables:
- name: "TABLE_NAME"
uri: "s3://BUCKET/TABLE/KEY"
option:
format: "csv"
To configure S3 credentials, you can set the following environment variables:
AWS_ENDPOINT_URL: The endpoint URL for your S3 providerAWS_REGION: The region where your S3 bucket is locatedAWS_SECRET_ACCESS_KEY: The secret access key from your S3 providerAWS_ACCESS_KEY_ID: The access key ID from your S3 provider
GCS
ROAPI can build tables from datasets hosted in GCS buckets. Configuration is similar to filesystem store:
tables:
- name: "TABLE_NAME"
uri: "gs://BUCKET/TABLE/KEY"
option:
format: "csv"
To configure GCS credentials, you can set the following environment variables if you are using service accont:
GOOGLE_SERVICE_ACCOUNT/GOOGLE_SERVICE_ACCOUNT_PATH: location of service account fileGOOGLE_SERVICE_ACCOUNT_KEY: JSON serialized service account keyGOOGLE_APPLICATION_CREDENTIALS: set by gcloud SDK- Google Compute Engine Service Account
- GKE Workload Identity
Azure Storage
ROAPI can build tables from datasets hosted in Azure Storage. Configuration is similar to filesystem store:
tables:
- name: "TABLE_NAME"
uri: "az://BUCKET/TABLE/KEY"
option:
format: "csv"
The supported url schemas are
abfs[s]://<container>/<path>az://<container>/<path>adl://<container>/<path>azure://<container>/<path>
To configure Azure credentials, you can set the following environment variables:
AZURE_STORAGE_ACCOUNT_NAMEAZURE_STORAGE_ACCOUNT_KEYAZURE_STORAGE_CLIENT_IDAZURE_STORAGE_TENANT_IDAZURE_STORAGE_SAS_KEYAZURE_STORAGE_TOKENAZURE_MSI_ENDPOINT/AZURE_IDENTITY_ENDPOINT: Endpoint to request a imds managed identity tokenAZURE_OBJECT_ID: Object id for use with managed identity authenticationAZURE_MSI_RESOURCE_ID: Msi resource id for use with managed identity authenticationAZURE_FEDERATED_TOKEN_FILE: File containing token for Azure AD workload identity federation
Databases
Thanks to the connector-x Rust crate, ROAPI is able to load tables from popular relational databases like MySQL, PostgreSQL and SQLite.
tables:
- name: "table_foo"
uri: "mysql://username:password@localhost:3306/database"
- name: "table_bar"
uri: "mysql://username:password@localhost:3306/database"
- name: "table_baz"
uri: "sqlite://path/to/sqlitelite/file"
With this, you can now write a single SQL query to join tables between MySQL, SQLite and local CSV files!
By default, ROAPI will use the provided table name as the table name to extract
data from the database. If you want to expose a specific database table with a
different name, you can use the option field to specify the original table
name like below:
tables:
- name: custom_table_name
uri: "sqlite://path/to/sqlitelite/file"
option:
table: original_table_name
format: sqlite
Postgres wire protocol
ROAPI uses the convergence Rust crate to read and write Postgres wire protocol. This means you will be able to query all tables loaded in ROAPI using any Postgres Clients as if ROAPI is a real Postgres database!
By default, ROAPI listens for Postgres traffic on address 127.0.0.1:5432, but
you can change it using the --addr-postgres command line argument or add the
following to your config file:
addr:
# binding address for TCP port that speaks Postgres wire protocol
postgres: 0.0.0.0:5432
Once ROAPI boots up, you can connect to it without authentication:
$ psql -h 127.0.0.1
psql (12.10 (Ubuntu 12.10-0ubuntu0.20.04.1), server 13)
WARNING: psql major version 12, server major version 13.
Some psql features might not work.
Type "help" for help.
houqp=> select 1;
Int64(1)
----------
1
(1 row)
houqp=>
See here for an example on how you can query data stored in a Google spreadsheet using the psql Postgres client.
HTTP API
Query frontends
ROAPI exposes a diverse set of interfaces through the HTTP protocol.
SQL
To query tables using a subset of standard SQL, send the query payload through
POST request to /api/sql endpoint. This is the only query interface that
supports table joins.
SQL query frontend is the more flexible and powerful compared to REST and GraphQL. It is the only query frontend that supports table joins.
SQL frontend supports [""] operator for accessing struct fields and array
element. For example struct_col["key1"]["key2"] or array_col[0].
REST
Query tables through REST API by sending GET requests to
/api/tables/{table_name}. Query operators are specified as query params.
REST query frontend currently supports the following query operators:
- columns
- sort
- limit
- filter
To sort column col1 in ascending order and col2 in descending order, set
query param to: sort=col1,-col2.
To find all rows with col1 equal to string 'foo', set query param to:
filter[col1]='foo'. You can also do basic comparisons with filters, for
example predicate 0 <= col2 < 5 can be expressed as
filter[col2]gte=0&filter[col2]lt=5.
GraphQL
To query tables through GraphQL, send the query through POST request to
/api/graphql endpoint.
GraphQL query frontend supports the same set of operators supported by REST query frontend. Here how is you can apply various operators in a query:
{
table_name(
filter: {
col1: false
col2: { gteq: 4, lt: 1000 }
}
sort: [
{ field: "col2", order: "desc" }
{ field: "col3" }
]
limit: 100
) {
col1
col2
col3
}
}
Key value lookup
Query key value stores through REST API by sending GET requests to
/api/kv/{kv_name}/{key}.
For example, the kvstore defined in the sample config can be queried like below:
$ curl -v localhost:8080/api/kv/spacex_launch_name/600f9a8d8f798e2a4d5f979e
Starlink-21 (v1.0)%
Schema
Get schemas for all tables:
curl localhost:8080/api/schema
Get schema for a specific table by name:
curl localhost:8080/api/schema/{TABLE_NAME}
Response serialization
By default, ROAPI encodes responses in JSON format, but you can request
different encodings by specifying the ACCEPT header:
curl -X POST \
-H 'ACCEPT: application/vnd.apache.arrow.stream' \
-d "SELECT launch_library_id FROM spacex_launches WHERE launch_library_id IS NOT NULL" \
localhost:8080/api/sql
ROAPI currently supports the following serialization formats:
application/jsonapplication/csvapplication/vnd.apache.arrow.fileapplication/vnd.apache.arrow.streamapplication/parquet